

{kind=link}
{kind=link}
{kind=link}
近红外漫反射光谱云芝提取物快速掺假识别研究
[涂红艳1  , 唐敏
, 唐敏2, * , 何晋浙3 , 邵平3 ]
, 唐敏, 何晋浙|
|


作者简介:涂红艳,硕士,从事食品检测技术应用研究工作,E-mail:19808164@qq.com。
为探索准确识别云芝提取物掺假(糊精)的方法,采用近红外漫反射光谱技术,对不同产地云芝提取物及掺假样品进行定性识别研究。在12 500~4 000 cm-1波段范围,采集样品的光谱,应用偏最小二乘判别法(PLS-DA)建立云芝提取物掺假识别模型。通过Kolmogorov-Smirnov法检验模型中云芝提取物分类变量值的分布规律,从而建立识别云芝提取物的最佳阈值区间,以实现对云芝提取物的掺假研究。结果表明,使用一阶导数(FD)和多元散射校正(MSC)的预处理方法,在主因子数为2,以及分别设置云芝提取物及掺假样品的分类变量为1、0时,云芝提取物的分类变量值服从正态分布,其最佳阈值区间为0.54~1.28(包含0.54和1.28)。建立偏最小二乘判别(PLS-DA)模型,对验证集样品进行识别,正确率可达100%。因此,该方法可较好地对云芝提取物进行掺假识别,同时为云芝提取物掺假识别模型的界限值确立、建立最佳阈值区间提供理论依据和方法。
云芝是一种常见的食用菌, 也是一种名贵的中药材[1]。其提取物中富含多种营养物质(多糖、萜类等), 可显著提高人体免疫力、增强机体耐缺氧能力、有效抑制肿瘤、辐射等作用。随着经济和生活水平的提高, 云芝提取物的需求量也在不断的增长[2]。然而市面上的生产厂家的良莠不齐、品质不一也给部分不良厂商的掺假谋利带来可乘之机[3]。常见利用的糊精、淀粉等廉价多糖的掺假, 不仅阻碍企业的发展, 同时也严重的损害到广大消费者的权益[4]。
传统的掺假鉴别方法主要有感官鉴别、显微鉴别、物理鉴别(排水法、热重分析法、微量升华法等)、化学鉴别(薄层色谱等)等[5, 6, 7]。然而, 这些方法的样品前处理过程复杂, 鉴别时间长且操作繁琐[8]。因此, 建立一种快速、无损的鉴别云芝提取物掺假的方法, 具有显著的实用价值。
近年来, 随着光谱学和计算机的迅速发展, 建立在近红外光谱技术上的无损检测, 具有分析速度快、效率高、成本低等诸多优点, 被广泛应用在食品等领域[9]。Ruth等[10]采用PLS-DA模型识别动物油脂和植物油脂, 其识别率可达100%。Chen等[11]通过建立PLS-DA模型对灵芝提取物进行溯源分析时, 提出以± 0.25作为界限值, 识别率达到100%。邵平等[12]在建立PLS-DA模型识别灵芝提取物和云芝提取物时, 提出以± 0.5作为界限值, 其识别率也达到100%。在建立识别模型中, 确立界限值, 建立识别模型的阈值区间, 将直接影响样品掺假与否的判定。但以上研究, 界限值的确立均为研究者自行设定而没有给出严谨的科学确立方法, 且对于恰好达到界限值的样品无法判定其有无掺假。为进一步探索界限值确立的方法, 建立最佳模型阈值区间, 并准确判定界限值样品的掺假与否, 本试验拟采用近红外漫反射光谱技术, 运用偏最小二乘判别模型并结合Kolmogorov-Smirnov检验方法, 对云芝提取进行掺假定性识别, 同时也为云芝提取物掺假识别模型的界限值确立、建立最佳阈值区间提供理论依据和方法。
试验中云芝提取物来自不同产地(东北、龙泉、长白山、安徽大别山、大兴安岭), 掺假用的糊精来自河南(河南大田食品添加剂有限公司), 共计140个样品, 云芝提取物和掺假样品各70个。运用直观分类的方法, 按照4:1的比例, 将所有的样品分为建模集和验证集, 其中建模集中样品数为56个, 验证集14个。仪器有德国布鲁克光学仪器公司(Bruker Optics Inc.)MPA TM傅里叶变换近红外光谱仪及称量瓶等附件, TE-InGaAs检测器, OPUS 6.5光谱采集。
将样品放置于环境温度为(20± 2)℃, 湿度为(50± 5)%的实验室24 h[13]。以仪器内置背景为参比, 将混合均匀的样品倒入到称量皿中压实, 采集样品的近红外漫反射光谱[14]。光谱波数范围为12 400~4 000 cm-1, 分辨率为8 cm-1, 扫描次数为16次, 取其平均光谱作为该样品的原始光谱[15]。
偏最小二乘判别法(PLS-DA)是一种用于判别分析的多变量统计分析方法。其原理是对不同处理样本(如观测样本、对照样本)的特性分别进行训练, 产生训练集, 并检验训练集的可信度[16]。在光谱分析中, PLS-DA算法可通过提取有效信息与标准值之间建立回归模型, 并采用交互验证的方式对模型验证可防止过拟合现象的出现[17]。
Kolmogorov-Smirnov检验[18]是一种基于累积分布函数, 用以检验1个经验分布是否符合某种理论分布或比较2个经验分布是否具有显著性差异检验。对来自样本数据的累计频数分布与特定理论分布比较, 通过两者间的差距比较推论样本取自某特定分布族[19]。
本试验采用TQ Analyst 8.6和SPSS 18分析软件对数据进行分析。
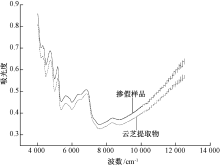
通过傅里叶变换近红外光谱仪采集全部样品的原始光谱, 分别求云芝提取物和掺假样品的平均光谱见图1。
 | 图1 样品原始近红外光谱图 |
由图1可知, 两者之间具有一些相同的吸收峰位, 但是两者之间具有明显的差异, 掺假样品的吸光度明显高于云芝提取物的吸光度。在8 000~4 000 cm-1二者近红外光谱差异较大, 这主要是与两者表面颜色和发色集团的差异有关; 在12 500~8 000 cm-1, 二者区别较小。这些差异的存在使得近红外漫反射光谱技术应用于二者的鉴别分析成为可能。
光谱数据中往往会含有环境以及仪器带来的噪声[20]。为去除光谱噪声以及基线漂移等的影响, 本试验分别采用多元散射校正(MSC)、变量标准化(SNV)、一阶导数(FD)、二阶导数(SD)、验证决定系数(R2)、校正均方根差(RMSECV)等方法进行预处理。不同的预处理方法建立识别模型的结果见表1。
| 表1 建模集中不同预处理的结果 |
由表1可知, 采用FD并结合MSC建立模型的R2为0.988, RMSECV为0.078, 此时RMSECV值最低, 预处理效果达到最优。
在FD并结合MSC预处理下, 建立PLS-DA模型, 采用预测残差平方和(pediction residual error sum of squares, PRESS)值来确定最佳主因子数。PLS-DA模型中PRESS值随主因子数的变化见图2, 在避免过拟合的前提下, 选取最低PRESS值所对应的主因子数。由图2可知, 在选择主因子数为2时, 预测残差平方和较低, 模型的优化效果较好。
 | 图2 PLS-DA模型PRES值随主因子数的变化 |
采用FD并结合MSC的预处理方法, 在最佳主成分因子数为2时, 设置云芝提取物的分类变量为1, 掺假样品的分类变量为0, 建立偏最小二乘判别模型。对模型的结果进行Kolmogorov-Smirnov检验。
由表2可知, 云芝提取物样品在Kolmogorov-Smirnov检验下, 其Asymp.Sig.(2-tailed)值为0.200, 大于显著水平0.05, 即云芝提取物的预测变量值服从均值μ 为0.912, 标准偏差σ 为0.124的正态分布; 同理可知, 掺假样品的预测变量值并不服从正态分布。由正态分布的规律及其3σ 原则可知, 云芝提取物分类变量值的最佳阈值区间可确定为0.54~1.28(包含0.54和1.28), 云芝提取物掺假样品变量值的阈值区间为小于0.54, 而阈值大于1.28的变量值即可判定为异常样品。
| 表2 样品正态性检验结果 |
运用建立的识别模型, 对验证集中28个样品(14个云芝提取物样品和14个掺假样品)进行预测, 结果如图3, 表3所示。
 | 图3 云芝提取物掺假识别预测结果 |
| 表3 PLS-DA模型中验证集的预测结果 |
由上述结果可知, 通过建立的PLS-DA模型, 对验证集中的14个云芝提取物样品分类准确度达到100%, 14个掺假样品的分类准确度也达到100%。因此, 采用该方法将二者准确识别可行, 同时也为PLS-DA模型确立界限值, 建立最佳阈值区间提供了一种可行的方法。
目前, 对云芝提取物掺假产品的鉴别试验尚无统一的标准[21, 22]。近红外光谱分析技术通过采集样品的漫反射光谱, 直接获取样品的信息, 从而可以达到对样品进行定量和定性的分析[23, 24]。本试验针对不同的云芝提取物及掺假样品的定性分析, 相对于原始光谱, 通过MSC并结合FD预处理的模型精确度可得到较好的提高, 剔除了一些无用的信息[25]。但模型中对云芝提取物的掺假样品没有建立准确的阈值区间范围[26]。其主要原因是没有分析出云芝提取物的掺假样品变量值分布规律, 针对云芝提取物掺假样品阈值区间的确定需要进一步的研究[27]。此外, 本研究采集的样本的品种和数量有限, 是否具有典型的代表性在后续工作中需进一步验证。
基于近红外漫反射光谱技术, 采用PLS-DA法结合Kolmogorov-Smirnov检验, 可作为一种快速、无损识别云芝提取物掺假的方法。研究采集不同产地的云芝提取物及掺假样品进行定性识别研究[28]。在12 500~4 000 cm-1波段, 采集样品的近红外漫反射光谱, 应用偏最小二乘判别法结合Kolmogorov-Smirnov检验模型中云芝提取物分类变量的分布规律, 建立云芝提取物掺假定性识别模型的最佳阈值区间。对验证集进行预测。结果表明, 结合Kolmogorov-Smirnov检验, 采用PLS-DA方法建立的识别模型能较好地对云芝提取物的掺假进行识别, 验证集样品的识别正确率为100%。因此, 偏最小二乘判别法结合Kolmogorov-Smirnov检验建立识别云芝提取物掺假模型是可行的, 同时也为云芝提取物掺假识别模型建立最佳阈值区间提供一种理论依据和方法。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|