基于扎根理论-相关-主成分分析的农民发展权评价指标体系构建
[刘龙青, 张国庆*  ]
]
]
|
|


作者简介:刘龙青(1974—),女,副教授,硕士,从事农民发展权、信息管理等研究工作。
研究用扎根理论初步构建4个主范畴74个子范畴的农民发展权评价指标体系,实现了指标的完整性要求;通过指标间的相关系数计算剔除相关性大的指标,实现了指标的独立性要求;运用主成分分析剔除因子载荷小的指标,实现了指标的显著性要求。研究结果表明,系统构建中国农民发展权评价指标体系,用尽可能少的指标反映出绝大多数评价信息,最终13个指标可反映初始74个指标体系95.4%的信息。
发展权是人们在社会生活中挖掘自身潜力、提高知识水平和应对复杂情况能力的权利[1]。农民发展权是关于农民发展机会均等和发展利益共享的权利[2]。由于历史和体制的原因, 中国农民还属于相对弱势群体, 很难平等地分享发展的成果。而解决这一问题的根本在于解决农民的发展权问题, 即农民的发展权利是否得到应有的尊重和保障[3]。2009年4月13日出台的《国家人权行动计划(2009— 2010年)》将“ 农民权益的保障” 单列一条, 彰显了国家确认和尊重农民发展权的决心。
农民发展权除了受自身素质影响外, 很大程度上要依靠政治、经济、文化等外围环境的支持和保障[4]。就农民发展权保障的现实来看, 我们还没有一个完整而系统的评价机制, 这必将成为制约发展权保障的一大瓶颈[5]。而评价农民发展权的前提条件就是要有一套较完整的评价指标体系。运用该指标体系, 可以评价和监测中国农民发展权的状态和程度, 可以为中国农民健康有序发展提供理论和方法指导。
目前, 对中国农民发展权评价理论的研究大都基于某个特定的视角展开。如汪习根等[6]从新常态视角, 研究发展权的实现, 指出要从单方面强调经济增长速度的观念转变到“ 持续发展” 的维度, 从经济结构调整带来的机遇和挑战转变到“ 发展正义” 的维度, 从传统手段转变到“ 发展权能” 的维度, 从干预模式转变到“ 政策平衡” 维度, 以谋求更充分的发展权。基于民主法治的视角评价, 即从农民政治参与行为要素的角度评价农民享有的政治权利程度, 认为村民自治是保障农民政治发展权的基础, 可通过完善立法, 加强制度供给、村务公开, 强化程序保障、创新机构, 加强组织保障以及培育公民意识, 提高自治能力等实现[7]。或基于经济的视角即享用经济发展权程度的评价[8]。也有基于法律的视角即发展权的法律保障程度的评价[9]。而对中国农民发展权评价的研究方法主要以定性描述为主, 也有学者研究了指标体系评价方法, 如邓秀华[10]构建了农民工的政治参与权评价指标体系。但现有的关于中国农民发展权评价指标体系往往只关注某一方面权利或某一特定群体, 缺少一套完整、可量化的全面评价中国农民发展权的指标体系。
为此, 本研究以中国农民为对象, 以农民发展权为评价内容, 构建中国农民发展权评价指标体系。研究分为初步构建与指标筛选两阶段, 初步构建就是要形成一个评价指标集, 该指标集要能全面反映农民发展权的方方面面, 完整性是该阶段的主要考虑因素。而指标筛选则是用尽可能少的指标反映尽可能多的信息, 可操作性、独立性和显著性是该阶段的主要考虑内容。可操作性即考虑数据的可获得, 对于无法获得或需要昂贵成本才能获得数据的指标予以剔除。独立性就是避免指标之间反映重复信息, 要求指标间相关程度小甚至不相关。而显著性则要求备选指标对评价结果有显著影响, 对评价结果贡献很小甚至微乎其微的指标将予以剔除。
数据分析主要遵循Charmaz的构建型扎根理论(The Constructivist’ s Approach to Grounded Theory), 因为该理论主要强调概念的自然涌现而非既有的程序化[11], 比较适合本研究。构建型扎根理论关键步骤包括开放性编码、理论编码和选择编码, 并通过理论饱和度检验确定所构建的评价指标体系。
扎根理论是从现象中归纳理论, 因此, 数据采集的真实性和完整性非常重要。农民发展权评价指标体系构建过程中的数据采集对象至少包括以下3类。第1类是农民发展权的直接感受对象即农民。第2类是农民发展权研究的领域专家。第3类是农民发展权的政策执行者即政府部门[12]。对数据进行整理与编码以抽取指标是扎根理论分析阶段最重要环节。开放编码就是将收集的资料打散再整合, 旨在总结概念和发现范畴。开放编码包括原始语句整理并形成独立的事件、将事件总结成相关概念、进一步将类似范畴的概念(群)提炼成范畴3方面内容。开放编码总结出概念和范畴后, 紧接着进行主轴编码, 它是发现并建立范畴间的联系, 并在此基础上形成核心范畴, 围绕核心范畴, 系统考虑其与其他范畴间的联系且予以验证, 并把概念化尚未发展完备的范畴补充完整, 形成初步的指标体系。
指标构建是否完整要通过理论饱和度检验, 其是判断是否停止采样的标准。即当收集新数据不再产生新的理论见解, 包括新的概念、新的范畴, 以及范畴新增的属性等, 理论即达到了饱和。
2.2.1 相关性分析思路
1)在对扎根理论构建的初步指标相关性分析之前, 要对指标进行标准化(无量纲)处理。
设dij为第j个评价对象第i个指标的值, m为被评价的对象数, 该指标标准化后的值xij, 若该指标为正值, 则指标的标准化公式:
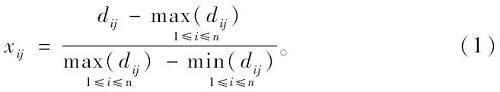
若该指标为负值, 则指标的标准化公式:

2)指标标准化后, 即可进行相关性分析。
相关分析目的是保证指标间的独立性, 其通过计算指标间的相关系数, 删除相关系数较大的指标(设定一个值Δ (0< Δ < 1), 如果
相关系数计算公式:
rij=
其中rij即为第i个指标和第j个指标间的相关系数, Oki为第k个评价对象的第i个指标的值,
2.2.2 主成分分析思路
主成分分析的目的是为了保证指标的显著性, 它是根据主成分Ej上因子负载
1)建立观测指标组合的主成分分析模型:
Ej=λ j1I1+λ j2I2+…+λ jnIn。(4)
其中:Ii表示第i个指标(i=1, 2, 3, …, n); Ej表示第j个主成分(j=1, 2, 3, …, m); λ ji为对应第j个特征值的第i个特征向量; m代表主成分个数; n代表指标数。
2)求标准化及相关分析后指标值的相关系数矩阵
ν i=λ i/
3)根据农民发展权评价的实际需要, 研究拟将特征值λ i按降序排列, 并选取累计方差贡献率≥ 85%的前m个特征值对应的主成分, 则第j个指标在第i个主成分上的因子负载矩阵θ ji:
aji=θ ji/
研究用数据方差表示指标信息含量的思路判断指标体系构建的合理性。设K为指标数据的协方差矩阵, trK为该矩阵的迹(主对角线上各指标方差之和); m为扎根分析构建的初始指标数量, n为相关和主成分分析后选取的指标个数。用筛选后的n个指标方差之和trKn与初始m个指标的方差之和trKm的比值(信息贡献率IC)作为判断指标构建的合理性标准, 该比值(信息贡献率)表示筛选后的指标能够反映初始指标信息的程度, 其计算公式:
IC=trKn/trKm。(7)
该公式是根据因子分析思想, 判断指标构建的合理性。如果能用30%以下的初始指标反映95%以上的原始信息, 则认为指标体系构建合理[13]。
3.1.1 抽样与样本描述
按籍贯、性别、年龄、学历、职业、民族、政治面貌等7个维度抽取访谈。选择安徽省舒城县外出务工者(农民工)和土地承包者各2人, 浙江省临安市山核桃经营者、遂昌县合作社社长和社员各2人, 浙江省义乌市淘宝创业者、四川省青川县农家乐经营者和务农者各2人, 领域专家6位(农业经济领域2位, 法学领域2位, 社会学领域2位), 政府官员6位(农业与农村工作办公室官员2位, 农业厅官员2位, 民政厅官员2位)。选择这几个地区的访谈对象也是基于笔者与其有一定的接触和交往。其中, 安徽舒城是通信作者的家乡, 可以直接访谈亲朋好友或经过他们介绍访谈对象。浙江是作者单位所在地, 2位作者也是浙江农民大学和浙江村官学院的主讲教师, 有很多深度接触当地农民的机会, 曾是四川省青川县的农业科技顾问, 所以本文研究者比较熟悉调查对象, 能够深入访谈。
3.1.2 访谈提纲与内容确定
访谈提纲是在国内外有关农民发展权及其评价研究的基础上, 结合本研究目标设计而成。涵盖农民个人及家庭基本信息, 经济、政治、文化和社会的发展权等部分。访谈包括58个开放式问题, 如您家的耕地有多少?可以自由流转吗?耕地制度是否合理?您参加过选举及其他参政议政活动吗?目的在于全面把握受访者的生存现状、发展观及其对发展权的认识和需求等信息。2016年2— 11月采集数据, 在访谈过程中尽可能将受访者的细微反应及时记录下来, 并对部分访谈内容进行录音。每人访谈1 h左右, 全部文档共7.5万字, 整理数据期间对部分叙述有疑问的再通过电话联系, 补充或修正。
3.1.3 开放编码
本研究首先对编码者进行培训, 然后将编码者分成3组, 每组独立编码。通过对访谈资料的开放性编码分析, 整理出728条原始语句, 提炼整理出74个概念, 归纳出4个范畴。开放编码形成的4个范畴如表1所示。
| 表1 开放性译码的概念与范畴 |
3.1.4 理论饱和度检验
本研究用12位农民、2位专家和2位政府官员共计16份访谈记录做理论饱和度检验, 编码结果没有出现新的概念和范畴, 范畴内也没有新的属性产生, 所以本研究所得出的范畴编码结果及农民发展权评价指标选择在理论上达到了饱和。
数据全部来自实地调查, 先根据初始指标体系设计调查问卷, 问卷包括农民收入、支出及其变化率、土地拥有量、土地流转及其收益分配, 政治参与渠道及其畅通率、文化活动项目及其满意度等33个题项82个问题。再选择浙江、安徽、四川等各类调查对象(务农农民、农民工、各类农民经营户等), 分发问卷307份, 回收293份, 剔除无效问卷29份, 有效问卷264份(S1~S264), 最后将问卷所有数据输入SPSS软件, 进行相关-主成分分析。
通过相关性分析删去相关系数较大的指标后, 再运用主成分分析进一步筛选剩余指标, 以累积方差贡献率≥ 85%时各主成分中因子负载绝对值较大的指标作为选取原则, 结果如表4所示。选取第一主成分中因子负载绝对值大于0.9和第二主成分中因子负载绝对值最大的指标, 计算结果保留指标为I1, 1、I1, 10、I1, 13、I1, 24、I2, 1、I2, 2、I2, 10、I3, 1 ; I3, 2、I3, 9、I4, 1、I4, 2和I4, 10。
| 表4 主成分方差贡献率 |
根据建立的指标体系合理性判定准则, 将筛选后指标方差之和trKn与初始指标的方差之和trKm代入公式(7), 得出筛选后的指标对初始指标的信息贡献率:
IC=trKn/trKm=0.954。
这一结果表明, 经过相关性和主成分分析, 从初步构建的74个指标中筛选出的13个指标能反映初始指标体系的95%以上的信息。构建的指标体系在反映了农民发展权评价的主要信息的同时, 指标数目大为精简。
系统构建了中国农民发展权评价指标体系, 首先用扎根理论初步构建了4个主范畴74个子范畴的农民发展权评价指标体系; 其次通过指标间的相关系数计算剔除了相关性较大的指标, 实现了指标的独立性需要; 最后运用主成分分析剔除了因子载荷小的指标, 实现了指标的显著性需要。
用尽可能少的指标反映出绝大多数评价信息, 研究结果表明, 用13个指标反映初始74个指标体系的约95.4%的信息, 通过本文的研究, 希望能为完善农民发展权评价指标体系, 准确评价农民发展权提供一定的帮助, 同时也希望能对政府政策制订与实施提供一定参考。促进了对农民发展权研究的理论指导。
在研究过程中, 尚未做到全面分析, 尤其是在不可观测的指标筛选上, 因为初步构建的指标体系中部分指标没有相关的统计数据可查, 所以被删除, 然而这些被删除指标中也许有独立性和显著性都较强的指标, 因此研究结论还是有一定的局限性, 今后可以采取大样本统计数据对本研究结论进行进一步论证和完善。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|