{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于灰色神经网络的茶叶产量预测算法
[胡克满a  , 胡海燕
, 胡海燕b ]
, 胡海燕|
|


作者简介:胡克满(1980—),男,浙江瑞安人,副教授,博士,研究方向为计算机视觉、机器学习,E-mail:hukeman@163.com。
通过分析茶叶产量影响因素,提出了一种非自然因素影响茶叶产量的预测模型。针对部分信息数据,运用灰色模型理论,结合神经网络系统对预测模型进行优化,给出了基于灰色神经网络的茶叶产量需求预测算法。实验证明,将实际产量和预测值进行比较和误差分析,该算法能够较好地实现茶叶产量的预测,具有一定的实际应用价值。
随着人们生活水平的日益提高, 人们对茶叶的需求也越来越大, 茶叶与可可、咖啡被视为世界上三大最受欢迎的饮料。根据历史记载, 我国在很早之前, 古人就对茶文化有一定的研究, 《茶经》等书籍是我国古人对茶文化进行研究留下的宝贵精神财富。我国也是茶叶重要的生产国和出口国[1]。据统计, 2016年我国茶叶产量为243万t, 比2015年增加了18.1万t[2]。我国茶叶生产地主要集中在亚热带地区, 自然气候对茶叶产量影响较大[3]。除了光照、雨水、温度、湿度、土壤等自然因素, 非自然因素也对茶叶产量有影响, 例如:茶叶采摘面积、城市居民茶叶消费价格指数、城镇居民人均可支配收入指数等人为因素引起的茶叶需求供求关系, 影响当年的茶叶产量。无论对茶农还是销售商而言, 每年茶叶的产量都是人们最为关注的因子之一。气候因素不受人为控制, 茶农和销售商的经济来源一定程度上受自然气候的影响, 随着卫星技术、计算机技术等的发展, 目前国内的气象预报也越来越准确, 茶叶生产者可以根据天气预报情况及时做出相应的补救措施。非自然因素引起的供需关系是大多数人始料不及的, 比如在过去几年中曾发生的大蒜、绿豆等因非自然因素导致的供需关系失衡。如何根据当年的非自然因素信息, 对茶叶产量进行有效预测, 从而避免不必要的经济损失具有一定的现实意义。
随着计算机和数学的发展, 有关预测模型倍受国内外专家学者关注。徐江等[4]证明了灰色理论在汽车造型预测中的可行性; LEE等[5]利用灰色理论对能源的消耗进行了预测; 孔雪等[6]对灰色预测模型应用现状进行了综述。张彪等[7]利用BP神经网络对苹果制干进行了评价; 户佐安等[8]运用BP神经网络对交通信息量进行了预测。杨锋等[9]运用灰色神经网络模型对强力旋压连杆的衬套屈服强度进行了预测; 李彬楠等[10]运用灰色理论和BP神经网络模型对土壤中的水分特征曲线进行了预测。综上所述, 无论是灰色理论还是BP神经网络都在预测模型中发挥了重要的作用, 但是由于计算和预测茶叶产量的过程受到很多因素影响, 目前未见有较好的预测模型报道。本研究通过对影响茶叶产量的诸多因素进行分析, 选取具有一定代表性的少量参数作为预测因变量。其中, 自然因素包括平均光照时间、平均降水量、平均气温、平均湿度、土壤成分、虫害等, 非自然因素包括人为茶叶采摘面积变化、城市居民茶叶消费价格指数、城镇居民人均可支配收入指数、茶叶认知等, 但是这些信息仍然属于部分信息。灰色系统理论可以在部分信息已知的条件下进行分析[11], 因此可以利用该理论对茶叶产量进行预测。神经网络的特征是具有适应性和自学能力强, 文章将神经网络与灰色理论结合进行优化, 从而提高预测茶叶产量的精确度。
灰色理论数学模型具有利用部分信息、计算简单等特征, 是我国学者邓聚龙教授提出的, 将模型中无规律的数据进行变换处理成为有序的序列。灰色理论数学模型针对原始数据序列进行累加, 使得数据具有一定的规律性, 再对其进行曲线拟合[12]。令时间数据序列为x0:
x0=(
灰度模型对时间数据序列x0做累加后获得新的数据序列x1, x1中第t时刻的数据为原始时间数据序列x0的前t项数据之和, 即:
x1=(
根据获得的新数据序列x1, 构建微分方程, 得到
式中:a为发展灰数, u为内生控制灰数。
整理方程得到解为:
t=n, n-1, …, 3, 2。 (5)
由此可见, 灰色数学模型是将时间序列数据x0直接转换成为微分方程, 利用系统信息进行模型量化, 可以在获得部分信息的情况下进行估算, 获得预测值。
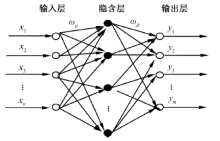
人工神经网络(artificial neural network, ANN)近几年来在人工智能方面得到广泛的应用, 其主要特征为类似人脑的神经元网络对信息进行处理, 按照一定的规律构建模型, 输入层与输出层之间以不同方式组成复杂的网络结构, 具有自适应性和自学习能力的特征。待处理的数据信息从输入层输入, 通过隐含层的计算处理到输出层输出结果, 任何一层的神经元装填及其数据计算结果都会影响后面一层的数据处理结果。通常在输出层和预期的结果进行比较, 根据误差反向传播多次迭代直至达到误差允许范围内, 或者完成设定的迭代次数[13]。BP神经网络拓扑结构如图1所示。预测函数的自变量为神经网络的输入参数, 函数的因变量为神经网络计算结果的输出值。因此, 神经网络构成的函数映射关系为由n个函数自变量从输入层输入, 产生m计算机结果从输出层输出。
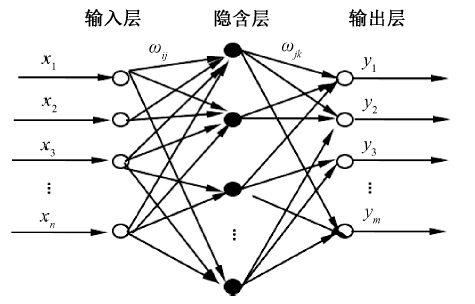 | 图1 BP神经网络拓扑结构 x1, x2, …, xn为BP神经网络的输入参数, 神经网络的计算结果表示为Y1, Y2, …, Ym, BP神经网络权值用ω ij和ω jk表示 |
对于多个变量参数的灰色神经网络模型优化方程可以表示为:
式(6)中, y1为系统模型的输出参数, y2, y3, …, yn为系统模型的输入参数, a, b1, b2, …, bn-1为系统模型的方程系数。其时间相应函数为:
z(t)=y1(0)e-at+(1-e-at)
令
d=
将式(7)和式(8)整理得到:
z(t)=
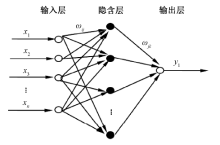
将整理得到的式(9)映射到BP神经网络中, 获得n个输入层参数及1个输出参数预测值的灰色神经网络优化模型, 图2为灰色神经网络拓扑结构图, 根据若干个自变量计算获得1个预测值。
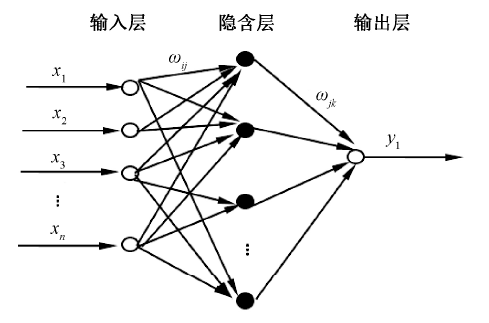 | 图2 灰色神经网络拓扑结构 x1, x2, …, xn为模型中的输入参数, ω ij、ω jk模型的权值, 输出层Y1为系统模型的输出参数 |
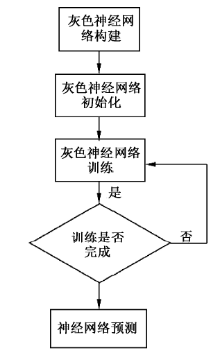
基于灰色神经网络的茶叶产量预测算法模型流程如图3所示。其中, 灰色神经网络构建的输入数据与输出数据确定灰色神经网络的结构。将非自然因素如茶叶采摘面积变化、城市居民茶叶消费价格指数、城镇居民人均可支配收入指数等作为输入数据, 构成三维数组; 预测值为当年的茶叶产量, 为1维数组。
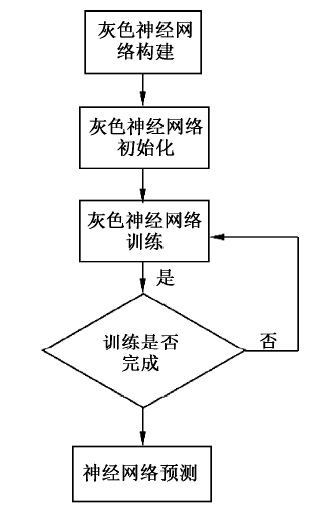 | 图3 灰色神经网络模型流程 |
系统模型以浙江省2001— 2011年的茶叶产量、采摘面积、城市居民茶叶消费价格指数、城镇居民人均可支配收入指数等作为输入数据和输出数据(表1)进行测试。所有数据均通过网络查询《中国年鉴统计数据库》获得, 原始数据均来自历年的《浙江统计年鉴》《中国统计年鉴》。
| 表1 2001— 2011年浙江省茶叶产量情况 |
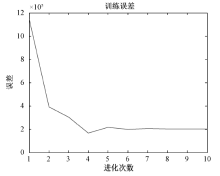
在预测过程中, 特别注意输入和输出数据的选择。本系统模型的训练数据集由2001— 2006年的原始数据组成, 系统模型通过多次迭代后结果如图4所示。
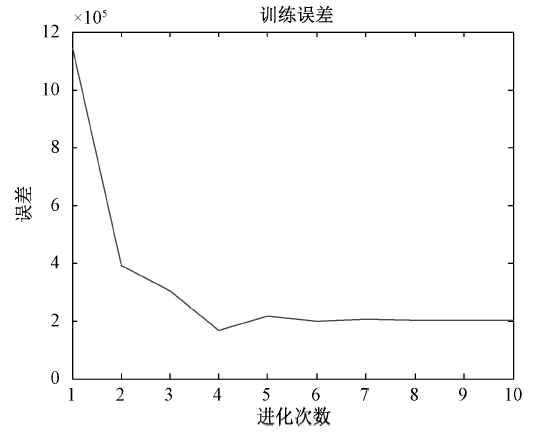 | 图4 系统模型多次迭代结果 |
将训练权值作为对2008— 2011年数据进行预测判断的参数, 并对茶叶预测产量与实际值进行比较, 结果见表2。由表2可知, 本文优化模型2008— 2011年预测产量与实际产量的平均相对误差为1.35%, 2011年预测值与实际值较接近, 而BP神经网络模型预测产量与实际产量的平均相对误差为4.47%, 可见本文优化模型可有效预测茶叶产量, 优化后的系统模型优于现有的BP神经网络算法。
| 表2 2008— 2011年浙江茶叶预测产量与实际产量 |
对茶农和经销商等用户而言, 茶叶产量直接影响其经济收入, 而影响茶叶产量的因素较多, 比如:光照、温度、湿度、土壤、虫害及非自然因素等, 众多影响因素导致人们无法很好地估算茶叶产量。本文通过灰度理论结合神经网络系统的适应性及自学习能力, 选取相对容易获得的采摘面积、城市居民茶叶消费价格指数、城镇居民人均可支配收入指数等数据作为估算参数, 通过优化的灰色神经网络模型进行产量预测, 结果表明, 优化后的系统模型能够较好预测当年的茶叶产量。由于提供的历年相关数据量有限, 故其迭代和收敛效果相对偏弱。如果系统模型的训练样本足够, 获得更多历年相关参数, 系统模型的迭代次数、函数的收敛性及预测值的评价误差率可能更优。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|